Links of the day
Monday, April 5, 2010
This blog has moved
This blog is now located at http://blog.gmarceau.qc.ca/.
You will be automatically redirected in 30 seconds, or you may click here.
For feed subscribers, please update your feed subscriptions to
http://blog.gmarceau.qc.ca/feeds/posts/default.
Monday, March 1, 2010
Americans have more investements in each other's health care than Canadians
Little known fact: Health care in America is funded by the government to a greater extends than in Canada. Between Medicaid, Medicare, Military Health Care, and emergency room services for the non-insured or the under-insured, the American government pays US$2,728 per person per year for health care. That's 23% more than the Canadian government expense (US$ 1,893.)
Ref: Wikipedia on the difference between the US and Canadian health care systems.
Ref: Wikipedia on the difference between the US and Canadian health care systems.
Friday, December 11, 2009
Why privacy matters
Bad week for privacy rights. The two companies which are running toweringly large repositories of private information, Facebook and Google, both messed up in the same week.
First there is Google. CEO Eric Schmidt, for a man of his stature and competence, as well as the person in control of the database servers that store my email, he came much too close to saying, "If you're not doing anything wrong, you don't have anything to hide." His version of the unfortunate phrase was
And then there is Facebook. With the introduction of their new privacy system, Facebook has published tons of private information about their users. Facebook has revealed the name, profile picture, current city, gender, networks, and the fan pages of everyone, including the information of those who had elected to keep these private.
I will not mince words. If this move, the revealing of information previously entrusted to be private, is not currently illegal under American law, it should be made so.
Snappletronics has a good collection of links discussing the issue, as well as suggestions on where to join protests that are currently being organized against Facebook.
Bruce Schneier has written an excellent piece on why privacy matters. In short, privacy protects us from abuses by those in power.
Privacy is absolutely essential for the members of the opposition party. If the government can spy on them, game over. Your democracy is dead; no challenger will ever win an election again. This is why Nixon had to be impeached. His actions were not as overt as a declaration of dictatorship, but the outcome of his spying activities, if left unchecked, would have been similar.
Privacy for journalists is also non-negotiable. Without journalists to hound the government and expose its troubles, your vote is blind. Your democracy might as well be based on tossing coins rather than votes. The press is, after all, the Fourth Estate. How many anonymous whistleblowers would there be if the journalists' phones were tapped?
Privacy for journalism students is also important. After all, any dirt gathered on them today can be used to intimidate them later in life, when they are threatening those in positions of power. And the same vein, law students must be protected, since they are likely to enter politics sometime during their career.
Similarly, political bloggers and activists will also be the targets of harassment. Their voice can be heard, and if it challenges the government, it may need to be silenced. Indeed, spying for the purpose of censorship might become the norm in the United States. Protesters now find police resistance immediately as they begin to assemble at the location of their rally. The police seem to know where to go. And they know because the phone lines were tapped.
Put yourself in the shoes of a politician. He has a pretty good gig. It pays well, it has great benefits. He enjoys the exhilaration of power and the occasional bribe. The only downside -- it's nerve-racking, really -- every four years he runs the risk of losing his job because someone is smearing his name in public. The best strategy is to start early and gather as much information as possible on the opposition. If no law stops him, he might as well tap the phone lines of would-be-bloggers and anyone likely to become an activist in the future. The information might come handy.
In short, anyone with a bone to grind against the government is in danger. And that's pretty much everyone.
First there is Google. CEO Eric Schmidt, for a man of his stature and competence, as well as the person in control of the database servers that store my email, he came much too close to saying, "If you're not doing anything wrong, you don't have anything to hide." His version of the unfortunate phrase was
If you have something that you don't want anyone to know, maybe you shouldn't be doing it in the first place. (via Boingboing)
And then there is Facebook. With the introduction of their new privacy system, Facebook has published tons of private information about their users. Facebook has revealed the name, profile picture, current city, gender, networks, and the fan pages of everyone, including the information of those who had elected to keep these private.
I will not mince words. If this move, the revealing of information previously entrusted to be private, is not currently illegal under American law, it should be made so.
Snappletronics has a good collection of links discussing the issue, as well as suggestions on where to join protests that are currently being organized against Facebook.
Bruce Schneier has written an excellent piece on why privacy matters. In short, privacy protects us from abuses by those in power.
Privacy is absolutely essential for the members of the opposition party. If the government can spy on them, game over. Your democracy is dead; no challenger will ever win an election again. This is why Nixon had to be impeached. His actions were not as overt as a declaration of dictatorship, but the outcome of his spying activities, if left unchecked, would have been similar.
Privacy for journalists is also non-negotiable. Without journalists to hound the government and expose its troubles, your vote is blind. Your democracy might as well be based on tossing coins rather than votes. The press is, after all, the Fourth Estate. How many anonymous whistleblowers would there be if the journalists' phones were tapped?
Privacy for journalism students is also important. After all, any dirt gathered on them today can be used to intimidate them later in life, when they are threatening those in positions of power. And the same vein, law students must be protected, since they are likely to enter politics sometime during their career.
Similarly, political bloggers and activists will also be the targets of harassment. Their voice can be heard, and if it challenges the government, it may need to be silenced. Indeed, spying for the purpose of censorship might become the norm in the United States. Protesters now find police resistance immediately as they begin to assemble at the location of their rally. The police seem to know where to go. And they know because the phone lines were tapped.
F.B.I. Watched Activist Groups, New Files Show**, New York Times, December 20, 2005
One F.B.I. document indicates that agents in Indianapolis planned to conduct surveillance as part of a "Vegan Community Project." Another document talks of the Catholic Workers group's "semi-communistic ideology." A third indicates the bureau's interest in Determining the location of a protest over llama fur planned by People for the Ethical Treatment of Animals.
Put yourself in the shoes of a politician. He has a pretty good gig. It pays well, it has great benefits. He enjoys the exhilaration of power and the occasional bribe. The only downside -- it's nerve-racking, really -- every four years he runs the risk of losing his job because someone is smearing his name in public. The best strategy is to start early and gather as much information as possible on the opposition. If no law stops him, he might as well tap the phone lines of would-be-bloggers and anyone likely to become an activist in the future. The information might come handy.
In short, anyone with a bone to grind against the government is in danger. And that's pretty much everyone.
Thursday, October 22, 2009
???!!??
Scheme allows punctuation marks in its identifiers, which allows for some funky naming convention. One of the most widely adopted convention is to name functions which return a boolean so that they end in ? (e.g. prime?), and name functions which have side effects to end in ! (e.g. set-random-seed!).
One problem with the Scheme language is that that convention hasn't been fleshed out any further. Here is the extension Tim and I designed.
(define (foo?? fn) ...) ;; Tests whether fn is a predicate for foo.
(define (foo!? fn) ...) ;; Tests whether fn is the setter for foo.
(define (foo?! fn) ...) ;; Sets a global predicates that will be used to test for foo's. For instance...
(define (true?! fn) ...) ;; Sets how we will be testing for true from now on, a.k.a. true?! redefines the behavior of if and cond.
(define (foo!! fn) ...) ;; Sets a setter for foo's. I'm not sure what this means. I'm tempted to say it is a setter for foo's that generates a yelling sound on the pc speaker as a side effect of the side effect.
It is also interesting to consider function names consisting of nothing but suffixes.
(define (? v) ...) ;; This is the predicate which doesn't specify what it is testing for. It is the vacuous predicate, It is the predicate that always returns true.
(define (?? fn) ...) ;; Tests whether the given function is a predicate. The ?? function is a kind of runtime type system. In other words, ?? applies the (any . -> . bool?) contract.
(define (!? fn) ...) ;; Tests whether fn might have side effects. !? is part of a compiler optimization pass.
(define (?! fn) ...) ;; Sets the global vacuous predicate. I'm not sure what this means either. I think it sets which logic you want to operate with. For a good time, set it to (lambda (v) false) and watch your entire model of computation collapse under the contradictions generated.
(define (! heap continuation) ...) ;; ! is the function that sets everything. It is the function that takes in a reified heap and a continuation and sets your interpreter state, wiping off the current state, then calls the continuation.
Defining function for names consisting of suffixes of three or more bangs and uhs (and nothing else) is left as an exercise to the reader.
While Scheme allow most punctuation marks in identifiers, somehow parentheses are forbidden. What a gross oversight. If we had it we could have define the smiley operator.
(define (:) v) ...) ;;; This is the smiley operator. It consumes a value and return a happy version of that value.
One problem with the Scheme language is that that convention hasn't been fleshed out any further. Here is the extension Tim and I designed.
(define (foo?? fn) ...) ;; Tests whether fn is a predicate for foo.
(define (foo!? fn) ...) ;; Tests whether fn is the setter for foo.
(define (foo?! fn) ...) ;; Sets a global predicates that will be used to test for foo's. For instance...
(define (true?! fn) ...) ;; Sets how we will be testing for true from now on, a.k.a. true?! redefines the behavior of if and cond.
(define (foo!! fn) ...) ;; Sets a setter for foo's. I'm not sure what this means. I'm tempted to say it is a setter for foo's that generates a yelling sound on the pc speaker as a side effect of the side effect.
It is also interesting to consider function names consisting of nothing but suffixes.
(define (? v) ...) ;; This is the predicate which doesn't specify what it is testing for. It is the vacuous predicate, It is the predicate that always returns true.
(define (?? fn) ...) ;; Tests whether the given function is a predicate. The ?? function is a kind of runtime type system. In other words, ?? applies the (any . -> . bool?) contract.
(define (!? fn) ...) ;; Tests whether fn might have side effects. !? is part of a compiler optimization pass.
(define (?! fn) ...) ;; Sets the global vacuous predicate. I'm not sure what this means either. I think it sets which logic you want to operate with. For a good time, set it to (lambda (v) false) and watch your entire model of computation collapse under the contradictions generated.
(define (! heap continuation) ...) ;; ! is the function that sets everything. It is the function that takes in a reified heap and a continuation and sets your interpreter state, wiping off the current state, then calls the continuation.
Defining function for names consisting of suffixes of three or more bangs and uhs (and nothing else) is left as an exercise to the reader.
While Scheme allow most punctuation marks in identifiers, somehow parentheses are forbidden. What a gross oversight. If we had it we could have define the smiley operator.
(define (:) v) ...) ;;; This is the smiley operator. It consumes a value and return a happy version of that value.
Thursday, September 17, 2009
Lucid dreaming practice gone wrong
At the bottom right corner of my screen, I saw 29:54. I thought to myself, ah my clock is b0rken, I must be dreaming! But no, it just was my editor telling me I'm on the 29th line (54th character.)
Sunday, May 31, 2009
Done! .... Nope! (ha! ha!)
Andrew Trumper posted an excellent analysis of how progress bars are all wrong (and what to do about it).
Saturday, May 30, 2009
The speed, size and dependability of programming languages
Note: This article has been updated. The earlier version was based on 2005 data, and included data from benchmarks that should not have been included. You should read this version, but if needed the the earlier version is also available.
The Computer Language Benchmarks Game is a collection of 429 programs, consisting of 13 benchmark reimplemented across 33 programming languages. It is a fantastic resource if you are trying to compare programming languages quantitatively. Which, oddly, very few people seems to be interested in doing.
The Benchmark Game spends a lot of efforts justifying itself against claims that the benchmarks are always flawed and that the whole exercise is pointless. I don't think it is. In fact, I've found that The Game is remarkably effective at predicting which forum hosts programmers annoyed at the slowness of their language, and that's good enough for me.
I was happy to find that in addition to speed The Game also publishes a source-code-size metric for each benchmark programs in each language. Thanks to this The Game let us at explore a fascinating aspect of programming language design: the tension that exist between expressiveness and performance. It is this tension that gives the expression "higher-level programming language" a pejorative connotation. When you are coding this high, you might be writing beautiful code, but you are so far away from the hardware you can't possibly get good performance, right?
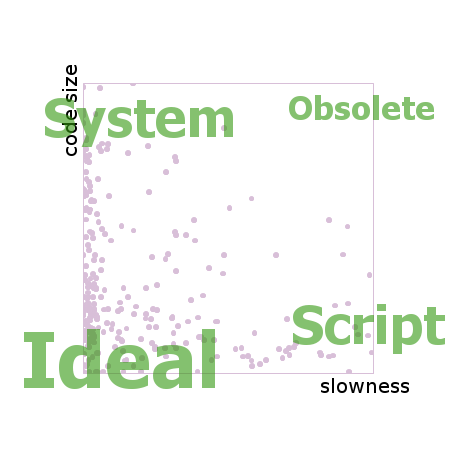
If you drew the benchmark results on an XY chart you could name the four corners. The fast but verbose languages would cluster at the top left. Let's call them system languages. The elegantly concise but sluggish languages would cluster at the bottom right. Let's call them script languages. On the top right you would find the obsolete languages. That is, languages which have since been outclassed by newer languages, unless they offer some quirky attraction that is not captured by the data here. And finally, in the bottom left corner you would find probably nothing, since this is the space of the ideal language, the one which is at the same time fast and short and a joy to use.
Each pinkish dot in this chart comes from one language implementing one benchmark solution, so there are 429 dots, minus a few missing implementations. Both axes show multipliers of worsening from best. That is, if a particular solution is not the best one, the axis show how many times worse it is when compared to the best. The barrier of dots on the left side means that it is common to have many solutions near the best performer. On the right side and beyond it, there are a number of distant points which are clipped out of view by the edge.
The distribution of pink points is more uniform along the Y axis (verbosity) than along the X (slowness), suggesting that the world has not hit a wall in the progression of the expressiveness of programming languages the way it has with performance.
Like many scientific datasets, the data coming from The Computer Language Benchmark Game is rich in shapes, insight and stories. In order to retain as much of the shape as possible, it is critical to avoid calculating averages, as averages tend to smooth over the data and hide interesting sources of variation. The average function does to numbers what Gaussian blur does to pictures. Avoid it if you want to see the edges.
One such source of variation that attracted my curiosity was dependability: how well does the language performs across a variety of tasks, such as those composing the benchmark suite? A language might be concise most of the time, but if once a month a quirk of the language forces the code to be five times as large as what it ought to be, it's a problem.
In order to show dependability, and to avoid relying on averages and standard deviations, I drew star charts in the following manner. Take, for example, the benchmarks for the programming language Scala, which is a mix of functional programming and Java that runs on the JVM. Starting with the previous chart and its 429 dots, I added a gray line from the XY position of each Scala benchmark to the position of the overall average of all the Scala programs.
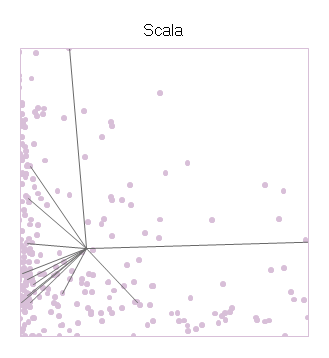
The center of the star is Scala's average performance, and the branches shoot out to the individual benchmarks. The resulting shape says something about Scala. On the X axis (slowness), the points often come close to the left wall, showing that Scala can take advantage of the optimizations done by the JVM. But the performance is not consistent, and in one case the performance is all the way to the right. On the Y axis (code size), we see that most of its scores are amongst the background crowd, but some of the faster benchmarks might have needed convolutions to reach the speed they have, including the one data point off the chart high above.
The next chart arranges the entire collection of the 33 programming languages available at The Computer Language Benchmark Game into a 6x6 grid. The chart is a so-called 'small multiples' design: each swatch in the grid has the same axes in the same scales as each other. It's the same setup as the one for Scala that we just saw. The 429 dots in the background are the same throughout. The intent is to make it easy to compare the shape of the star between languages (across the page), and against the general trend (in the background).
The swatch of the languages are grouped into columns according to their overall performance. Thus the fastest languages are in the first column on the left and the slowest are on the right. Within each column the swatches are sorted by average code size, with the best one at the bottom. In this way, the disposition of the grid mimics the axes within the swatches.

This chart is a treasure of narratives.
The languages in the first column all have tall thin pogo-stick stars. They show strikingly consistent performance, maxing out the CPU times after times, with the exception of one gcc benchmark and one g++ benchmark. Java stands proudly among that group, having earned its place after 10 years of intense research in run-time optimization. Their code sizes, on the other hand, are spread all over.
In the rightmost two columns we find many bushy stars, flat and wide. These are the scripting languages whose communities have not invested as much effort into building optimizing compilers for their language as they have spent tweaking its expressiveness. There are, however, a few spectacular exceptions. Lua, which has always been noted for its good performance among scripting languages, shows a much rounder star in the swatch at (4, 1), counting from the bottom left. Even better, the star of Luajit (3, 1) settles itself in the coveted bottom left corner, next to two academics celebrities Ocaml at (2, 1) and Clean (1, 1).
I am told that writing high-performance programs in Haskell is a bit of a black art, and that the tweaks introduced to boost the performance occupy a lot of code space. Perhaps because of this, the Haskell star at (2, 5) is extremely tall, reaching from the very top the very bottom, while having decent performance over all. Clean is a lazy language just like Haskell, but its star is much more compact, especially in code size, as if a huge effort of optimization had paid off and that it is now possible to write performance code naturally in Clean.
Both Python (5, 1) and Ruby (5, 3) can claim many of the smallest programs in the collection, but so does Firefox 3.5's JavaScript (5, 2). Yet, only the V8 implementation of JavaScript (4, 1) can make a claim at having reliable good performance. Its star has very few points though. It will remain to be seen whether it can maintain its good profile as more benchmarks gets implemented.
No, it does not. In the following chart, the ordering is the same as in the large chart. Languages which include functional features such as lambda, map, and tail call optimization are highlighted in green. The C and C++ compilers are in blue. The greens are spread all over, with more presence in the left (top and bottom) than on the right. Ultimately the first factor of performance is the maturity of the implementation.

I used a data table from The Game's website for the charts above (you will need to copy/paste that page into a csv file.) The code to generate the charts runs in PLT Scheme (MzScheme) v4.1.5.
Despite it not having a particularly remarkable spot on this performance chart, I code in PLT Scheme because it has a fantastic macro system. I also have wrists problems, so coding in Scheme lets me use my ergonomic editor DivaScheme.
The Computer Language Benchmarks Game is a collection of 429 programs, consisting of 13 benchmark reimplemented across 33 programming languages. It is a fantastic resource if you are trying to compare programming languages quantitatively. Which, oddly, very few people seems to be interested in doing.
The Benchmark Game spends a lot of efforts justifying itself against claims that the benchmarks are always flawed and that the whole exercise is pointless. I don't think it is. In fact, I've found that The Game is remarkably effective at predicting which forum hosts programmers annoyed at the slowness of their language, and that's good enough for me.
I was happy to find that in addition to speed The Game also publishes a source-code-size metric for each benchmark programs in each language. Thanks to this The Game let us at explore a fascinating aspect of programming language design: the tension that exist between expressiveness and performance. It is this tension that gives the expression "higher-level programming language" a pejorative connotation. When you are coding this high, you might be writing beautiful code, but you are so far away from the hardware you can't possibly get good performance, right?
If you drew the benchmark results on an XY chart you could name the four corners. The fast but verbose languages would cluster at the top left. Let's call them system languages. The elegantly concise but sluggish languages would cluster at the bottom right. Let's call them script languages. On the top right you would find the obsolete languages. That is, languages which have since been outclassed by newer languages, unless they offer some quirky attraction that is not captured by the data here. And finally, in the bottom left corner you would find probably nothing, since this is the space of the ideal language, the one which is at the same time fast and short and a joy to use.
Each pinkish dot in this chart comes from one language implementing one benchmark solution, so there are 429 dots, minus a few missing implementations. Both axes show multipliers of worsening from best. That is, if a particular solution is not the best one, the axis show how many times worse it is when compared to the best. The barrier of dots on the left side means that it is common to have many solutions near the best performer. On the right side and beyond it, there are a number of distant points which are clipped out of view by the edge.
The distribution of pink points is more uniform along the Y axis (verbosity) than along the X (slowness), suggesting that the world has not hit a wall in the progression of the expressiveness of programming languages the way it has with performance.
Like many scientific datasets, the data coming from The Computer Language Benchmark Game is rich in shapes, insight and stories. In order to retain as much of the shape as possible, it is critical to avoid calculating averages, as averages tend to smooth over the data and hide interesting sources of variation. The average function does to numbers what Gaussian blur does to pictures. Avoid it if you want to see the edges.
One such source of variation that attracted my curiosity was dependability: how well does the language performs across a variety of tasks, such as those composing the benchmark suite? A language might be concise most of the time, but if once a month a quirk of the language forces the code to be five times as large as what it ought to be, it's a problem.
In order to show dependability, and to avoid relying on averages and standard deviations, I drew star charts in the following manner. Take, for example, the benchmarks for the programming language Scala, which is a mix of functional programming and Java that runs on the JVM. Starting with the previous chart and its 429 dots, I added a gray line from the XY position of each Scala benchmark to the position of the overall average of all the Scala programs.
The center of the star is Scala's average performance, and the branches shoot out to the individual benchmarks. The resulting shape says something about Scala. On the X axis (slowness), the points often come close to the left wall, showing that Scala can take advantage of the optimizations done by the JVM. But the performance is not consistent, and in one case the performance is all the way to the right. On the Y axis (code size), we see that most of its scores are amongst the background crowd, but some of the faster benchmarks might have needed convolutions to reach the speed they have, including the one data point off the chart high above.
The next chart arranges the entire collection of the 33 programming languages available at The Computer Language Benchmark Game into a 6x6 grid. The chart is a so-called 'small multiples' design: each swatch in the grid has the same axes in the same scales as each other. It's the same setup as the one for Scala that we just saw. The 429 dots in the background are the same throughout. The intent is to make it easy to compare the shape of the star between languages (across the page), and against the general trend (in the background).
The swatch of the languages are grouped into columns according to their overall performance. Thus the fastest languages are in the first column on the left and the slowest are on the right. Within each column the swatches are sorted by average code size, with the best one at the bottom. In this way, the disposition of the grid mimics the axes within the swatches.
This chart is a treasure of narratives.
The languages in the first column all have tall thin pogo-stick stars. They show strikingly consistent performance, maxing out the CPU times after times, with the exception of one gcc benchmark and one g++ benchmark. Java stands proudly among that group, having earned its place after 10 years of intense research in run-time optimization. Their code sizes, on the other hand, are spread all over.
In the rightmost two columns we find many bushy stars, flat and wide. These are the scripting languages whose communities have not invested as much effort into building optimizing compilers for their language as they have spent tweaking its expressiveness. There are, however, a few spectacular exceptions. Lua, which has always been noted for its good performance among scripting languages, shows a much rounder star in the swatch at (4, 1), counting from the bottom left. Even better, the star of Luajit (3, 1) settles itself in the coveted bottom left corner, next to two academics celebrities Ocaml at (2, 1) and Clean (1, 1).
I am told that writing high-performance programs in Haskell is a bit of a black art, and that the tweaks introduced to boost the performance occupy a lot of code space. Perhaps because of this, the Haskell star at (2, 5) is extremely tall, reaching from the very top the very bottom, while having decent performance over all. Clean is a lazy language just like Haskell, but its star is much more compact, especially in code size, as if a huge effort of optimization had paid off and that it is now possible to write performance code naturally in Clean.
Both Python (5, 1) and Ruby (5, 3) can claim many of the smallest programs in the collection, but so does Firefox 3.5's JavaScript (5, 2). Yet, only the V8 implementation of JavaScript (4, 1) can make a claim at having reliable good performance. Its star has very few points though. It will remain to be seen whether it can maintain its good profile as more benchmarks gets implemented.
Does introducing functional features kill performance?
No, it does not. In the following chart, the ordering is the same as in the large chart. Languages which include functional features such as lambda, map, and tail call optimization are highlighted in green. The C and C++ compilers are in blue. The greens are spread all over, with more presence in the left (top and bottom) than on the right. Ultimately the first factor of performance is the maturity of the implementation.
Source code
I used a data table from The Game's website for the charts above (you will need to copy/paste that page into a csv file.) The code to generate the charts runs in PLT Scheme (MzScheme) v4.1.5.
Despite it not having a particularly remarkable spot on this performance chart, I code in PLT Scheme because it has a fantastic macro system. I also have wrists problems, so coding in Scheme lets me use my ergonomic editor DivaScheme.
![]()
Subscribe to Posts [Atom]