Links of the day
Saturday, May 30, 2009
The speed, size and dependability of programming languages
Note: This article has been updated. The earlier version was based on 2005 data, and included data from benchmarks that should not have been included. You should read this version, but if needed the the earlier version is also available.
The Computer Language Benchmarks Game is a collection of 429 programs, consisting of 13 benchmark reimplemented across 33 programming languages. It is a fantastic resource if you are trying to compare programming languages quantitatively. Which, oddly, very few people seems to be interested in doing.
The Benchmark Game spends a lot of efforts justifying itself against claims that the benchmarks are always flawed and that the whole exercise is pointless. I don't think it is. In fact, I've found that The Game is remarkably effective at predicting which forum hosts programmers annoyed at the slowness of their language, and that's good enough for me.
I was happy to find that in addition to speed The Game also publishes a source-code-size metric for each benchmark programs in each language. Thanks to this The Game let us at explore a fascinating aspect of programming language design: the tension that exist between expressiveness and performance. It is this tension that gives the expression "higher-level programming language" a pejorative connotation. When you are coding this high, you might be writing beautiful code, but you are so far away from the hardware you can't possibly get good performance, right?
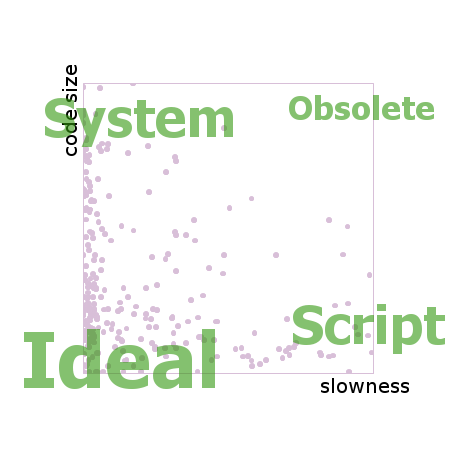
If you drew the benchmark results on an XY chart you could name the four corners. The fast but verbose languages would cluster at the top left. Let's call them system languages. The elegantly concise but sluggish languages would cluster at the bottom right. Let's call them script languages. On the top right you would find the obsolete languages. That is, languages which have since been outclassed by newer languages, unless they offer some quirky attraction that is not captured by the data here. And finally, in the bottom left corner you would find probably nothing, since this is the space of the ideal language, the one which is at the same time fast and short and a joy to use.
Each pinkish dot in this chart comes from one language implementing one benchmark solution, so there are 429 dots, minus a few missing implementations. Both axes show multipliers of worsening from best. That is, if a particular solution is not the best one, the axis show how many times worse it is when compared to the best. The barrier of dots on the left side means that it is common to have many solutions near the best performer. On the right side and beyond it, there are a number of distant points which are clipped out of view by the edge.
The distribution of pink points is more uniform along the Y axis (verbosity) than along the X (slowness), suggesting that the world has not hit a wall in the progression of the expressiveness of programming languages the way it has with performance.
Like many scientific datasets, the data coming from The Computer Language Benchmark Game is rich in shapes, insight and stories. In order to retain as much of the shape as possible, it is critical to avoid calculating averages, as averages tend to smooth over the data and hide interesting sources of variation. The average function does to numbers what Gaussian blur does to pictures. Avoid it if you want to see the edges.
One such source of variation that attracted my curiosity was dependability: how well does the language performs across a variety of tasks, such as those composing the benchmark suite? A language might be concise most of the time, but if once a month a quirk of the language forces the code to be five times as large as what it ought to be, it's a problem.
In order to show dependability, and to avoid relying on averages and standard deviations, I drew star charts in the following manner. Take, for example, the benchmarks for the programming language Scala, which is a mix of functional programming and Java that runs on the JVM. Starting with the previous chart and its 429 dots, I added a gray line from the XY position of each Scala benchmark to the position of the overall average of all the Scala programs.
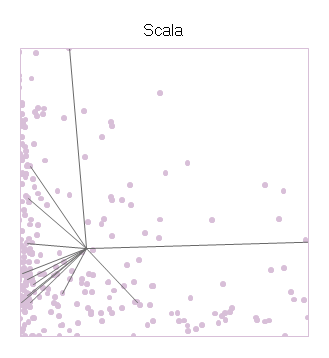
The center of the star is Scala's average performance, and the branches shoot out to the individual benchmarks. The resulting shape says something about Scala. On the X axis (slowness), the points often come close to the left wall, showing that Scala can take advantage of the optimizations done by the JVM. But the performance is not consistent, and in one case the performance is all the way to the right. On the Y axis (code size), we see that most of its scores are amongst the background crowd, but some of the faster benchmarks might have needed convolutions to reach the speed they have, including the one data point off the chart high above.
The next chart arranges the entire collection of the 33 programming languages available at The Computer Language Benchmark Game into a 6x6 grid. The chart is a so-called 'small multiples' design: each swatch in the grid has the same axes in the same scales as each other. It's the same setup as the one for Scala that we just saw. The 429 dots in the background are the same throughout. The intent is to make it easy to compare the shape of the star between languages (across the page), and against the general trend (in the background).
The swatch of the languages are grouped into columns according to their overall performance. Thus the fastest languages are in the first column on the left and the slowest are on the right. Within each column the swatches are sorted by average code size, with the best one at the bottom. In this way, the disposition of the grid mimics the axes within the swatches.

This chart is a treasure of narratives.
The languages in the first column all have tall thin pogo-stick stars. They show strikingly consistent performance, maxing out the CPU times after times, with the exception of one gcc benchmark and one g++ benchmark. Java stands proudly among that group, having earned its place after 10 years of intense research in run-time optimization. Their code sizes, on the other hand, are spread all over.
In the rightmost two columns we find many bushy stars, flat and wide. These are the scripting languages whose communities have not invested as much effort into building optimizing compilers for their language as they have spent tweaking its expressiveness. There are, however, a few spectacular exceptions. Lua, which has always been noted for its good performance among scripting languages, shows a much rounder star in the swatch at (4, 1), counting from the bottom left. Even better, the star of Luajit (3, 1) settles itself in the coveted bottom left corner, next to two academics celebrities Ocaml at (2, 1) and Clean (1, 1).
I am told that writing high-performance programs in Haskell is a bit of a black art, and that the tweaks introduced to boost the performance occupy a lot of code space. Perhaps because of this, the Haskell star at (2, 5) is extremely tall, reaching from the very top the very bottom, while having decent performance over all. Clean is a lazy language just like Haskell, but its star is much more compact, especially in code size, as if a huge effort of optimization had paid off and that it is now possible to write performance code naturally in Clean.
Both Python (5, 1) and Ruby (5, 3) can claim many of the smallest programs in the collection, but so does Firefox 3.5's JavaScript (5, 2). Yet, only the V8 implementation of JavaScript (4, 1) can make a claim at having reliable good performance. Its star has very few points though. It will remain to be seen whether it can maintain its good profile as more benchmarks gets implemented.
No, it does not. In the following chart, the ordering is the same as in the large chart. Languages which include functional features such as lambda, map, and tail call optimization are highlighted in green. The C and C++ compilers are in blue. The greens are spread all over, with more presence in the left (top and bottom) than on the right. Ultimately the first factor of performance is the maturity of the implementation.

I used a data table from The Game's website for the charts above (you will need to copy/paste that page into a csv file.) The code to generate the charts runs in PLT Scheme (MzScheme) v4.1.5.
Despite it not having a particularly remarkable spot on this performance chart, I code in PLT Scheme because it has a fantastic macro system. I also have wrists problems, so coding in Scheme lets me use my ergonomic editor DivaScheme.
The Computer Language Benchmarks Game is a collection of 429 programs, consisting of 13 benchmark reimplemented across 33 programming languages. It is a fantastic resource if you are trying to compare programming languages quantitatively. Which, oddly, very few people seems to be interested in doing.
The Benchmark Game spends a lot of efforts justifying itself against claims that the benchmarks are always flawed and that the whole exercise is pointless. I don't think it is. In fact, I've found that The Game is remarkably effective at predicting which forum hosts programmers annoyed at the slowness of their language, and that's good enough for me.
I was happy to find that in addition to speed The Game also publishes a source-code-size metric for each benchmark programs in each language. Thanks to this The Game let us at explore a fascinating aspect of programming language design: the tension that exist between expressiveness and performance. It is this tension that gives the expression "higher-level programming language" a pejorative connotation. When you are coding this high, you might be writing beautiful code, but you are so far away from the hardware you can't possibly get good performance, right?
If you drew the benchmark results on an XY chart you could name the four corners. The fast but verbose languages would cluster at the top left. Let's call them system languages. The elegantly concise but sluggish languages would cluster at the bottom right. Let's call them script languages. On the top right you would find the obsolete languages. That is, languages which have since been outclassed by newer languages, unless they offer some quirky attraction that is not captured by the data here. And finally, in the bottom left corner you would find probably nothing, since this is the space of the ideal language, the one which is at the same time fast and short and a joy to use.
Each pinkish dot in this chart comes from one language implementing one benchmark solution, so there are 429 dots, minus a few missing implementations. Both axes show multipliers of worsening from best. That is, if a particular solution is not the best one, the axis show how many times worse it is when compared to the best. The barrier of dots on the left side means that it is common to have many solutions near the best performer. On the right side and beyond it, there are a number of distant points which are clipped out of view by the edge.
The distribution of pink points is more uniform along the Y axis (verbosity) than along the X (slowness), suggesting that the world has not hit a wall in the progression of the expressiveness of programming languages the way it has with performance.
Like many scientific datasets, the data coming from The Computer Language Benchmark Game is rich in shapes, insight and stories. In order to retain as much of the shape as possible, it is critical to avoid calculating averages, as averages tend to smooth over the data and hide interesting sources of variation. The average function does to numbers what Gaussian blur does to pictures. Avoid it if you want to see the edges.
One such source of variation that attracted my curiosity was dependability: how well does the language performs across a variety of tasks, such as those composing the benchmark suite? A language might be concise most of the time, but if once a month a quirk of the language forces the code to be five times as large as what it ought to be, it's a problem.
In order to show dependability, and to avoid relying on averages and standard deviations, I drew star charts in the following manner. Take, for example, the benchmarks for the programming language Scala, which is a mix of functional programming and Java that runs on the JVM. Starting with the previous chart and its 429 dots, I added a gray line from the XY position of each Scala benchmark to the position of the overall average of all the Scala programs.
The center of the star is Scala's average performance, and the branches shoot out to the individual benchmarks. The resulting shape says something about Scala. On the X axis (slowness), the points often come close to the left wall, showing that Scala can take advantage of the optimizations done by the JVM. But the performance is not consistent, and in one case the performance is all the way to the right. On the Y axis (code size), we see that most of its scores are amongst the background crowd, but some of the faster benchmarks might have needed convolutions to reach the speed they have, including the one data point off the chart high above.
The next chart arranges the entire collection of the 33 programming languages available at The Computer Language Benchmark Game into a 6x6 grid. The chart is a so-called 'small multiples' design: each swatch in the grid has the same axes in the same scales as each other. It's the same setup as the one for Scala that we just saw. The 429 dots in the background are the same throughout. The intent is to make it easy to compare the shape of the star between languages (across the page), and against the general trend (in the background).
The swatch of the languages are grouped into columns according to their overall performance. Thus the fastest languages are in the first column on the left and the slowest are on the right. Within each column the swatches are sorted by average code size, with the best one at the bottom. In this way, the disposition of the grid mimics the axes within the swatches.
This chart is a treasure of narratives.
The languages in the first column all have tall thin pogo-stick stars. They show strikingly consistent performance, maxing out the CPU times after times, with the exception of one gcc benchmark and one g++ benchmark. Java stands proudly among that group, having earned its place after 10 years of intense research in run-time optimization. Their code sizes, on the other hand, are spread all over.
In the rightmost two columns we find many bushy stars, flat and wide. These are the scripting languages whose communities have not invested as much effort into building optimizing compilers for their language as they have spent tweaking its expressiveness. There are, however, a few spectacular exceptions. Lua, which has always been noted for its good performance among scripting languages, shows a much rounder star in the swatch at (4, 1), counting from the bottom left. Even better, the star of Luajit (3, 1) settles itself in the coveted bottom left corner, next to two academics celebrities Ocaml at (2, 1) and Clean (1, 1).
I am told that writing high-performance programs in Haskell is a bit of a black art, and that the tweaks introduced to boost the performance occupy a lot of code space. Perhaps because of this, the Haskell star at (2, 5) is extremely tall, reaching from the very top the very bottom, while having decent performance over all. Clean is a lazy language just like Haskell, but its star is much more compact, especially in code size, as if a huge effort of optimization had paid off and that it is now possible to write performance code naturally in Clean.
Both Python (5, 1) and Ruby (5, 3) can claim many of the smallest programs in the collection, but so does Firefox 3.5's JavaScript (5, 2). Yet, only the V8 implementation of JavaScript (4, 1) can make a claim at having reliable good performance. Its star has very few points though. It will remain to be seen whether it can maintain its good profile as more benchmarks gets implemented.
Does introducing functional features kill performance?
No, it does not. In the following chart, the ordering is the same as in the large chart. Languages which include functional features such as lambda, map, and tail call optimization are highlighted in green. The C and C++ compilers are in blue. The greens are spread all over, with more presence in the left (top and bottom) than on the right. Ultimately the first factor of performance is the maturity of the implementation.
Source code
I used a data table from The Game's website for the charts above (you will need to copy/paste that page into a csv file.) The code to generate the charts runs in PLT Scheme (MzScheme) v4.1.5.
Despite it not having a particularly remarkable spot on this performance chart, I code in PLT Scheme because it has a fantastic macro system. I also have wrists problems, so coding in Scheme lets me use my ergonomic editor DivaScheme.
» posted by Guillaume Marceau @ 9:16 AM 
Comments:
<< Home

YARV and JRuby aren't marked green, but they're exactly the same as Ruby. Actually YARV is basically the forerunner to the official Ruby now.
Also, when mentioning Ruby, YARV is a fairer comparison. Ruby 1.9.1 is now the official production version of Ruby, which YARV represents (sort of - there's a new set of Shootouts that has 1.9.1 directly). The uber-slow benchmarks on your charts are from Ruby 1.8 which is still in common usage but is not representative of Ruby as a whole.
Also, when mentioning Ruby, YARV is a fairer comparison. Ruby 1.9.1 is now the official production version of Ruby, which YARV represents (sort of - there's a new set of Shootouts that has 1.9.1 directly). The uber-slow benchmarks on your charts are from Ruby 1.8 which is still in common usage but is not representative of Ruby as a whole.
Thank you for the superb "tabula rasa" of computer program solutions expressed in different languages. Personally I feel a taint of morbid attraction when I pitch a language against another considering that they exist to complement each other, not to deprecate each other away. Kudos for the Java chart. Is fast in some given cases and very slow in others. That is true in so many levels!
I'd like to mention that of the functional features you mentioned, lua has them all except a native map function. But it does have lambda expressions and tail calls, and map can be implemented in like 10 lines.
What Fun!
I like the originality so much that I'm loath to offer corrections, but there are some basic facts...
1) You seem to have used the out-of-date Pentium 4 measurements some of which were made in 2005 and none of which were made later than mid-2008.
Some language implementations have changed quite a bit since then.
2) The benchmarks game spends effort drawing attention to the ways in which benchmarks are flawed.
"Flaw" has a range of meaning from "imperfection, blemish" through to "invalidating defect".
3) No, the benchmarks game does not publish a line-of-code metric, we stopped doing that becomes it just encourages obfuscated programs.
Instead, the benchmarks game publishes a source-code gzip bytes metric.
I like the originality so much that I'm loath to offer corrections, but there are some basic facts...
1) You seem to have used the out-of-date Pentium 4 measurements some of which were made in 2005 and none of which were made later than mid-2008.
Some language implementations have changed quite a bit since then.
2) The benchmarks game spends effort drawing attention to the ways in which benchmarks are flawed.
"Flaw" has a range of meaning from "imperfection, blemish" through to "invalidating defect".
3) No, the benchmarks game does not publish a line-of-code metric, we stopped doing that becomes it just encourages obfuscated programs.
Instead, the benchmarks game publishes a source-code gzip bytes metric.
Also, hipe is erlang's native-code compiler. The language is the same, the compatibility is slightly different.
What, no FORTRAN (or COBOL) ?
Obviously a hole in the original data, not the analysis, but FORTRAN is still common in scientific analysis and it would have been interesting.
I don't see PL1, Algol, Lisp, Smalltalk, Logo either.
Obviously a hole in the original data, not the analysis, but FORTRAN is still common in scientific analysis and it would have been interesting.
I don't see PL1, Algol, Lisp, Smalltalk, Logo either.
I wonder what the benchmark cluster for "D" would look; the explicit goal of the language is to be fast and functional.
Andrew Daviel wrote What, no FORTRAN (or COBOL) ? ... I don't see PL1, Algol, Lisp, Smalltalk, Logo either.If you have eyes to see then you will see Fortran and you will see Lisp and you will see (several) Smalltalks.
In the last chart, Perl should be green. Is supports lambda and map natively. It can also do tail call recursion using goto &NAME or goto &LABEL, or by carefully optimizing away tail calls. These are all manual techniques rather than compiler optimizations, but if you're designing recursive code it's not that much more difficult to include tail call optimization.

I am just wondering what version of Ruby 1.9 was used (I understand it is YARV on th diagram). Was it pre-relase or 1.9.1? If it was pre-release, then judging from performance improvements in final version, YARV would move much more to bottom left corner ;).
Updates: Linked to the definition of the loc metric. Mentionned Yarv in the text. Turn Lua green. Ruby stays gray since it does not mandate TCO.
@Isaac Gouy: Damn, these are from 2005? Can you point me to the up-to-date data file?
@Isaac Gouy: Damn, these are from 2005? Can you point me to the up-to-date data file?
Amazing stuff!
I'd really love to see these graphs automated and stuck on the "The Computer Language Benchmarks Game" site.
I'd really love to see these graphs automated and stuck on the "The Computer Language Benchmarks Game" site.
Andrew Daviel wrote about missing Fortran. Well, there are at least two of them, but hidden under the compiler's names, "ifc" and "g95", and perhaps a few more I am not familiar with.
Nice work, but remember that
a language is not chosen for
a project on these two dimensions alone.
Experience, tools, compatability,
platform, even community (ie help) factor in. Also, given that useful programs will have long lives, efficiency may change over time.
And of course, management irrationality is always fun.
a language is not chosen for
a project on these two dimensions alone.
Experience, tools, compatability,
platform, even community (ie help) factor in. Also, given that useful programs will have long lives, efficiency may change over time.
And of course, management irrationality is always fun.
Hi there, nice job.
Just wanted to make a quick correction... Perl has features such as map and closures and they're widely used. As matter of fact, this is true for a long time now (not sure since when, but at least since Perl 5.8, which was released some 8 or 9 years ago).
So you should probably mark it as green.
Just wanted to make a quick correction... Perl has features such as map and closures and they're widely used. As matter of fact, this is true for a long time now (not sure since when, but at least since Perl 5.8, which was released some 8 or 9 years ago).
So you should probably mark it as green.
Isaac Gouy wrote "If you have eyes to see then you will see Fortran and you will see Lisp and you will see (several) Smalltalks."
Okay, that didn't help at all. I see one scheme. What are the other Lisp's listed as?
Okay, that didn't help at all. I see one scheme. What are the other Lisp's listed as?
If hipe is erlang's native code compiler (HIgh Performance Erlang), then it should be green too, just like erlang is.
I notice the scatter diagram weights strongly towards the left. As a result, differences between the higher performing language implementations are obscured. It would be interesting to replot the x axis so that it showed percentile, rather than absolute numbers.
Guillaume Marceau > Can you point me to the up-to-date data file?
There are 4 different data sets.
Here's x86 one-core
There are 4 different data sets.
Here's x86 one-core
Guillaume Marceau > Updates: Linked to the definition of the loc metric.
As long as you keep talking about loc your readers will wrongly think you actually mean loc.
FAQ: How is the game scored?
On 3 measures - time, memory use and source code size.
As long as you keep talking about loc your readers will wrongly think you actually mean loc.
FAQ: How is the game scored?
On 3 measures - time, memory use and source code size.
Updates: Posted the 2009 data at the bottom of the article. Turned loc into "source code size". Fixed the coordinates of Psyco.
Thanks!
Thanks!
Incidentally, the benchmarks game data files include data for programs which for various reasons are filtered out when the web pages are generated
- different algorithms
- programs which are not as fast as others in the same language but are interesting
- programs which don't give the expected output
- programs which take longer than some timeout, currently 1 hour
etc
- different algorithms
- programs which are not as fast as others in the same language but are interesting
- programs which don't give the expected output
- programs which take longer than some timeout, currently 1 hour
etc
It seems like a language comparison must also somehow include end-to-end efficiency of application development. E.g. does the developer work at a primitive or object level, is there large library support, are their good tools for design/code/debug/optimize - etc. But those metrics should simply be benchmarked or measured (as in this article) rather than attempt to abstractly qualify them. It seems like this is a good approach taken here, to find a few good metrics and just measure them and determine a way to contrast results rather than a theoretical comparison.
It would also be helpful in this article to put a table with a single line description of each language (e.g. "g95 is a version of FORTRAN").
Thanks - Keep it going !
It would also be helpful in this article to put a table with a single line description of each language (e.g. "g95 is a version of FORTRAN").
Thanks - Keep it going !
@Issac
I am guessing that you work on The Game? I would be grateful if you could add a column to the data file to indicate which language should no be displayed. I also would appreciate columns for the long name and descriptions of each language, like Foothill is asking for.
I am guessing that you work on The Game? I would be grateful if you could add a column to the data file to indicate which language should no be displayed. I also would appreciate columns for the long name and descriptions of each language, like Foothill is asking for.
Thank you! A most interesting piece of work!
Now I'm really interested to run all of these benchmarks locally :) (there goes my copious free time...).
Now I'm really interested to run all of these benchmarks locally :) (there goes my copious free time...).
A nice set of benchmarks. I took a look at the updated charts and saw one of my favourite languages (Occam) which appears in this chart is no longer there. Gah! KROC (the x86 implementation of Occam) is at least as worthy of a place as some of the other languages, particularly given the results on this older chart.
There are other languages I'd like to see, sure. Cilk++ versus vanilla Gnu C++ would be interesting. If Intel's C/C++ is worthy, then perhaps Green Hills would be too, as that is a major vendor in high-end computing. It would be good to know if it is worthy of such a place.
Someone mentioned PL/1- well, there is a PL/1 frontend for GCC, but it's not very mature and the sole developer probably needs some help. Commercial PL/1 compilers for Linux exist, but cost something like $15,000 per seat - at least, that's what it was the last time I checked. That's a bit steep for benchmarking.
Haskell is interesting. I didn't spot which implementation was tested, but I know there are several out there. Maybe testing a wider range would produce interesting results.
There are other languages I'd like to see, sure. Cilk++ versus vanilla Gnu C++ would be interesting. If Intel's C/C++ is worthy, then perhaps Green Hills would be too, as that is a major vendor in high-end computing. It would be good to know if it is worthy of such a place.
Someone mentioned PL/1- well, there is a PL/1 frontend for GCC, but it's not very mature and the sole developer probably needs some help. Commercial PL/1 compilers for Linux exist, but cost something like $15,000 per seat - at least, that's what it was the last time I checked. That's a bit steep for benchmarking.
Haskell is interesting. I didn't spot which implementation was tested, but I know there are several out there. Maybe testing a wider range would produce interesting results.
Nice post. I would like to say that Python supports several 'functional' features such as list comprehensions, map, filter, reduce, lambda, closures, and lazy evaluation.
gcc also has extensions to support closures.
gcc also has extensions to support closures.
Pretty fascinating - I've just spent the past 30 minutes examining your charts, and the game data.
I'm not sure about the narratives you read into the data though. I took at the code for a couple of the languages that I actually know a bit about - Scala, and OCaml, and I observed a couple of things.
OCaml appears to get generally better scores on both dimensions than Scala. That's unsurprising in the 'slowness dimension', but I invite the reader to compare the source code of the tests for compactness by eye.
To my eye, the scala versions are significantly more compact, and more expressive. Some of the OCaml versions look like miniature virtual machines in their own right, and obscure the solution from the casual reader's eye.
To me this points to a couple of things - obviously the style and competence of the programmers make a significant difference to both metrics. To really be able to make narratives out of these charts, I think you need a couple more dimensions. I would suggest:
1. The number of lines of code written in the given language by the programmers involved before they wrote the game code.
2. An 'erdos number' for the programmers who wrote the code connecting back to the language designer.
Fuzzy as these are they would give some idea about the depth of experience the programmers have in writing expressive code in their chosen language. I would speculate that some of the younger languages with larger communities do worse partly because the programmers have less experience with writing optimal code. Perhaps by the same token, older languages whose designers are still active but with smaller communities do disproportionately well because the programmers are more likely to be experts.
Another serious confounding factor is the use of GZIP to determine the weight or expressiveness of the program. The performance of GZIP on text depends a lot on the ability to identify and reuse a dictionary of words to reconstruct the text.
Some programming styles, particularly ones that sacrifice compactness for performance by using repetition will be massively advantaged by the use of GZIP. Use of repetitive words, and even copy and paste code - which may be performant but unmaintainable and hard to understand will be overvalued, whereas concise code where each word is distinct and meaningful will be disproportionately penalized.
I won't venture to say how these factors affect the particular rankings, but I would suggest that the results should be taken as a starting point rather than anything conclusive, and that any reasoning or arguing based on these results needs to carefully take into account contextual factors.
I'm not sure about the narratives you read into the data though. I took at the code for a couple of the languages that I actually know a bit about - Scala, and OCaml, and I observed a couple of things.
OCaml appears to get generally better scores on both dimensions than Scala. That's unsurprising in the 'slowness dimension', but I invite the reader to compare the source code of the tests for compactness by eye.
To my eye, the scala versions are significantly more compact, and more expressive. Some of the OCaml versions look like miniature virtual machines in their own right, and obscure the solution from the casual reader's eye.
To me this points to a couple of things - obviously the style and competence of the programmers make a significant difference to both metrics. To really be able to make narratives out of these charts, I think you need a couple more dimensions. I would suggest:
1. The number of lines of code written in the given language by the programmers involved before they wrote the game code.
2. An 'erdos number' for the programmers who wrote the code connecting back to the language designer.
Fuzzy as these are they would give some idea about the depth of experience the programmers have in writing expressive code in their chosen language. I would speculate that some of the younger languages with larger communities do worse partly because the programmers have less experience with writing optimal code. Perhaps by the same token, older languages whose designers are still active but with smaller communities do disproportionately well because the programmers are more likely to be experts.
Another serious confounding factor is the use of GZIP to determine the weight or expressiveness of the program. The performance of GZIP on text depends a lot on the ability to identify and reuse a dictionary of words to reconstruct the text.
Some programming styles, particularly ones that sacrifice compactness for performance by using repetition will be massively advantaged by the use of GZIP. Use of repetitive words, and even copy and paste code - which may be performant but unmaintainable and hard to understand will be overvalued, whereas concise code where each word is distinct and meaningful will be disproportionately penalized.
I won't venture to say how these factors affect the particular rankings, but I would suggest that the results should be taken as a starting point rather than anything conclusive, and that any reasoning or arguing based on these results needs to carefully take into account contextual factors.
These benchmarks have been thoroughly debunked several times in the past. See this thread, for example: http://www.javalobby.org/java/forums/t86371.html?start=30
Or just google for "language shootout". It's not that the people who run this are just incompetent, including JVM startup times but not including time for libc to load from disk. It's that they actively allow and even encourage cheating. For example, at least one of the "C" benchmarks actually uses hand-coded assembly (libgmp), and rather than stick to the obvious "program must be written in the language it's listed under" rule, the site maintainer suggests that the "Java" benchmark could be changed to also use assembly. This is all in the thread listed above.
After several of these debunkings over the years, they had to change the name from "the language shootout" to something else, as any quick google will show that these benchmarks are completely bogus.
Or just google for "language shootout". It's not that the people who run this are just incompetent, including JVM startup times but not including time for libc to load from disk. It's that they actively allow and even encourage cheating. For example, at least one of the "C" benchmarks actually uses hand-coded assembly (libgmp), and rather than stick to the obvious "program must be written in the language it's listed under" rule, the site maintainer suggests that the "Java" benchmark could be changed to also use assembly. This is all in the thread listed above.
After several of these debunkings over the years, they had to change the name from "the language shootout" to something else, as any quick google will show that these benchmarks are completely bogus.
Guillaume Marceau > I would be grateful if you could add a column to the data file to indicate which language should no be displayed. I also would appreciate columns for the long name and descriptions of each language
How comical that you should start thinking about what the base data might mean after you have published your analysis :-)
1) If the status column is non-zero then that's a bad thing - don't include those rows.
2) If the program is listed in exclude.csv then that's a bad thing - don't include those rows.
3) The websites only include the benchmarks and languages listed in the corresponding include.csv4) There's often more than one program for each benchmark in the same language - just take the fastest. Whether or not other slower programs are shown is arbitrary - some will be removed quickly, and some won't.
5) Look-up file extension to language implementation
How comical that you should start thinking about what the base data might mean after you have published your analysis :-)
1) If the status column is non-zero then that's a bad thing - don't include those rows.
2) If the program is listed in exclude.csv then that's a bad thing - don't include those rows.
3) The websites only include the benchmarks and languages listed in the corresponding include.csv4) There's often more than one program for each benchmark in the same language - just take the fastest. Whether or not other slower programs are shown is arbitrary - some will be removed quickly, and some won't.
5) Look-up file extension to language implementation
Andy > thoroughly debunked
Not.
Andy > the "Java" benchmark could be changed to also use...
The fastest Java pidigits program does use Gmp.
Andy > had to change the name from "the language shootout"
I changed the name after Virginia Tech - April 16, 2007.
Not.
Andy > the "Java" benchmark could be changed to also use...
The fastest Java pidigits program does use Gmp.
Andy > had to change the name from "the language shootout"
I changed the name after Virginia Tech - April 16, 2007.
Very nice job, but Ocaml should be green, not blue. It's got lambdas, maps, and tail call optimization.
For those wanting a development environment to test luajit in, http://www.murga-projects.com/murgaLua/index.html should also work with luajit, the latest build 0.7.0 is at http://www.my-plan.org/storage/private/murgaLua-snapshot.tar.gz
This is quite wonderful! Thankyou.
Did you just do this for a laugh? You should immediately contact your local University and suggest a PhD dissertation.
Cheers, al.
Did you just do this for a laugh? You should immediately contact your local University and suggest a PhD dissertation.
Cheers, al.
It would be intresting to see the graphs for solutions coded in the "best practices" style for the respective languages. Many of the shootout solutions, like Haskell, go to great lengths to disallow lazy evaluation or other features in the name of speed. While these numbers are very cool, it doesn't necessarily show me what typical results I will see after using a language.
Since you are running the X-axis as a factor of performance slowdown when compared to the best, try a logarithmic scale on that axis. It should help to prevent the squashing on the left edge.
A "global average slowness" on X axis is flawed. To compute the center of the star, a better choice would be to Sum(language test time)/Sum(overall fastest language test time) instead of 1/(number of test) * Sum( language/fastest language for each test).
A more readeable X axis would be simply the time (may be log-scaled to fit in)
Idem for Y axis if "Verbosity" is a ratio (it is written "codesize" at the beginning, is it true ?) (but do no log-scale both at the same time !)
Finally, values on the axis would help to read you curve (only on first line and column languages)
A more readeable X axis would be simply the time (may be log-scaled to fit in)
Idem for Y axis if "Verbosity" is a ratio (it is written "codesize" at the beginning, is it true ?) (but do no log-scale both at the same time !)
Finally, values on the axis would help to read you curve (only on first line and column languages)
I would say you are more-or-less correct in your analysis of Haskell. There are a few masters going at the benchmarks. The most prolific is Don Stewart, who almost uses Haskell as a low-level language and achieves very fast (albeit verbose) programs.
There are also a few points when GHC is exactly suited to the problem at hand, and the brilliant compiler frontend whips and mangles the program into tiny, efficient code. But there are only a handful of people who understand the compiler well enough to predict when it will do such a thing, and even those who do are hard pressed to create an elegant program suited to it.
There are also a few points when GHC is exactly suited to the problem at hand, and the brilliant compiler frontend whips and mangles the program into tiny, efficient code. But there are only a handful of people who understand the compiler well enough to predict when it will do such a thing, and even those who do are hard pressed to create an elegant program suited to it.
Very interesting visualization. I've spent much to much time paging back and forth between languages on the Shootout, trying to get a feel for syntax and looking at the conciseness stats.
Thanks Guillaume.
Thanks Guillaume.
Wonderful work!
As I'm a .NET developer, it would be nice to compare how its IL stacks up against the other languages on its native platform (windows).
Again, great analysis!
As I'm a .NET developer, it would be nice to compare how its IL stacks up against the other languages on its native platform (windows).
Again, great analysis!
A great visualization of expressiveness viz performance. A good way to defend or choose a language :)
Amazing work.
Amazing work.
john said...
Isaac Gouy wrote "If you have eyes to see then you will see Fortran and you will see Lisp and you will see (several) Smalltalks."
Okay, that didn't help at all. I see one scheme. What are the other Lisp's listed as?I can see 'squeak' and 'stx' as at least the two smalltalks!
Isaac Gouy wrote "If you have eyes to see then you will see Fortran and you will see Lisp and you will see (several) Smalltalks."
Okay, that didn't help at all. I see one scheme. What are the other Lisp's listed as?I can see 'squeak' and 'stx' as at least the two smalltalks!
Where in the hell is Delphi!. It is one of the top 10 major languages in the programming world.
And don't give me Fpascal, only a monkey would ever use it.
Get it right!, no-one is interested in obscure languages.
And don't give me Fpascal, only a monkey would ever use it.
Get it right!, no-one is interested in obscure languages.
By the statement "functional languages include lambda, map, and TCO" you really should include perl. It does have all those things. As does Groovy (more natively than perl) and if you squint hard enough then so does C.
Also based just on TCO then Scala is out since it only mandates TCO for tail-calls to the same function and not mutually recursive ones. Until Scheme mandated TCO many Lisp implementations didn't use it and it would be hard to argue that's not a functional language.
I'd suggest you change your notion of a functional language to the ones that use functions and functional composition as the principle means of computation. If the first thought on how to solve some tricky problem isn't to start using or building higher-order functions then I think it's a hard call to say you are using an FP language.
Perl's out, Lua's out. Groovy is out. Ruby is out. Scala is in.
Alternately you could name those languages that allow functions to be treated as first class data in which case Perl is in, Lua's in, Groovy is in, Ruby is in, and Scala is in.
Whatever you decide be consistent.
http://en.wikipedia.org/wiki/Functional_programming
Also based just on TCO then Scala is out since it only mandates TCO for tail-calls to the same function and not mutually recursive ones. Until Scheme mandated TCO many Lisp implementations didn't use it and it would be hard to argue that's not a functional language.
I'd suggest you change your notion of a functional language to the ones that use functions and functional composition as the principle means of computation. If the first thought on how to solve some tricky problem isn't to start using or building higher-order functions then I think it's a hard call to say you are using an FP language.
Perl's out, Lua's out. Groovy is out. Ruby is out. Scala is in.
Alternately you could name those languages that allow functions to be treated as first class data in which case Perl is in, Lua's in, Groovy is in, Ruby is in, and Scala is in.
Whatever you decide be consistent.
http://en.wikipedia.org/wiki/Functional_programming
Another metric that I would like to see in comparisons like this would be something to display the average time needed to fix a bug as well as the maximum time needed to fix a bug.
Several years ago, I was doing a one-programmer job to move a large medical-laboratory instrumentation control from DIBOL to Ada. I was using the open-source GNAT Ada compiler and the DIBOL compiler from Synergex, as I had to maintain the old DIBOL program while writing its replacement in Ada. Unfortunately, the project was canceled after three months of work when the laboratory was sold, but I was able to compare DIBOL and Ada with respect to the time needed to find and fix a bug, and Ada was a huge win. Most DIBOL bugs took a full day to run down, and the worst-case bugs required 4 days to run down. During the same three months, the large majority of Ada bugs were found and fixed in 15 minutes or less, and the most difficult one took 4 hours.
Unfortunately, gathering such statistics for all of the languages in the charts would be an immense task and really would be material for an MS dissertation at the very least.
Several years ago, I was doing a one-programmer job to move a large medical-laboratory instrumentation control from DIBOL to Ada. I was using the open-source GNAT Ada compiler and the DIBOL compiler from Synergex, as I had to maintain the old DIBOL program while writing its replacement in Ada. Unfortunately, the project was canceled after three months of work when the laboratory was sold, but I was able to compare DIBOL and Ada with respect to the time needed to find and fix a bug, and Ada was a huge win. Most DIBOL bugs took a full day to run down, and the worst-case bugs required 4 days to run down. During the same three months, the large majority of Ada bugs were found and fixed in 15 minutes or less, and the most difficult one took 4 hours.
Unfortunately, gathering such statistics for all of the languages in the charts would be an immense task and really would be material for an MS dissertation at the very least.
In these days of ever faster hardware plus faster hw architectures sheer speed is only a small factor in choosing a language. More important are:
-- quality and power of development tools, class libraries, and frameworks.
-- Support for the language itself. (i.e., who maintains and enhances it?)
-- Availability of sw engineering talent experienced with programming in it.
-- Whether the language features and syntax encourage writing reliable, easy-to-maintain code.
-- quality and power of development tools, class libraries, and frameworks.
-- Support for the language itself. (i.e., who maintains and enhances it?)
-- Availability of sw engineering talent experienced with programming in it.
-- Whether the language features and syntax encourage writing reliable, easy-to-maintain code.
Echoing what Luke said about Haskell/GHC, the results definitely show that you can tune GHC code to have excellent performance but you wind up writing really strange code (see the Mandelbrot benchmark @ http://shootout.alioth.debian.org/u64q/benchmark.php?test=mandelbrot&lang=ghc&id=2).
Super solid analysis. Impressive that you don't claim to know much about Haskell and yet were able to identify the Haskell tuning benefit from your charts.
Super solid analysis. Impressive that you don't claim to know much about Haskell and yet were able to identify the Haskell tuning benefit from your charts.
Bivariate Histograms would be useful to see. The only thing that jumps out at me is the average and the max and min.
What seems most fascinating about this is the new, creative way to visualize and quantify the benchmark data. Yes, there are more dimensions, and yes, the data isn't perfect. However, the method of visualization is very cool. I'm curious, how could one add some of the additional dimesions mentioned above (maintainability would be a great one) without sacrificing visual usability?
I think it would be much more meaningful to rank languages by the median score rather than the mean. By using the mean, you allow one or two outliers to drastically change the ranking of a language. Given how the implementations were written (contributed by random people), an outlier probably says more about the abilities of the person who wrote that implementation than about the language it's written in.
For more than 50 years, we've known (and I've known personally) that it's possible to write crappy programs in any language, and good programs in any language, by just about any measure of crappy and good.
As far as the speed measure is concerned, we've also known that real speed differences come from design, not coding.
Or, perhaps, requirements. What is the programmer trying to accomplish? In the end, anything not worth doing is not worth doing fast. (You might want to look at The Psychology of Computer Programming, written before most of these languages were invented, or their inventors were even born.
As far as the speed measure is concerned, we've also known that real speed differences come from design, not coding.
Or, perhaps, requirements. What is the programmer trying to accomplish? In the end, anything not worth doing is not worth doing fast. (You might want to look at The Psychology of Computer Programming, written before most of these languages were invented, or their inventors were even born.
Another very important consideration that seems to have been ignored is future support, program maintenance by someone other than the original author. People costs are much higher than system costs.
Peter > I think it would be much more meaningful to rank languages by the median score rather than the mean.
Like this?
Like this?
Guillaume Marceau > I would be grateful if ...
Summary Data for each set of measurements is now available on each corresponding website.
Summary Data for each set of measurements is now available on each corresponding website.
Also wondering is there a reason why Delphi / TurboPascal is not included here? Given its high performance in specific areas it seems a strange miss.
Was this only for OpenSource?
Paul
Was this only for OpenSource?
Paul
"Where in the hell is Delphi!. It is one of the top 10 major languages in the programming world.
And don't give me Fpascal, only a monkey would ever use it.
Get it right!, no-one is interested in obscure languages."Yes, where is Delphi? But Georgie, speak for for yourself. I develop software in both Delphi and Lazarus/FPC and believe it or not, there are very interesting things you can do in the latter (and no, I don't feel like a monkey).
And don't give me Fpascal, only a monkey would ever use it.
Get it right!, no-one is interested in obscure languages."Yes, where is Delphi? But Georgie, speak for for yourself. I develop software in both Delphi and Lazarus/FPC and believe it or not, there are very interesting things you can do in the latter (and no, I don't feel like a monkey).
Re: Delphi
Isaac's site only uses language implementations which can be run under Linux, and Delphi is Windows only. Free Pascal is quite similar, though.
This comment from the FAQ is also interesting:
"We are unable to publish measurements for many commercial language implementations simply because their license conditions forbid it."
I'm curious which implementations were actually excluded due to license problems.
Isaac's site only uses language implementations which can be run under Linux, and Delphi is Windows only. Free Pascal is quite similar, though.
This comment from the FAQ is also interesting:
"We are unable to publish measurements for many commercial language implementations simply because their license conditions forbid it."
I'm curious which implementations were actually excluded due to license problems.
Ian Osgood > I'm curious which implementations were actually excluded due to license problems.
Hi Ian, long time.
iirc there was a period when the Intel license excluded publication of benchmark measurements.
You'll find some others if you browse the old feature requests.
Hi Ian, long time.
iirc there was a period when the Intel license excluded publication of benchmark measurements.
You'll find some others if you browse the old feature requests.
Suggestions:
1) Move the language name closer to the chart it labels - currently the label is almost mid-way between 2 charts.
2) Don't tell us - show us. Don't tell us "are highlighted in green... are in blue..." - show us a blank green chart labeled 'functional' and a blank blue chart labeled '{...}' and a blank gray chart labeled...
3) Put the up-to-date data in a new blog entry with it's own analysis - and correct this blog entry now you have filtered data.
1) Move the language name closer to the chart it labels - currently the label is almost mid-way between 2 charts.
2) Don't tell us - show us. Don't tell us "are highlighted in green... are in blue..." - show us a blank green chart labeled 'functional' and a blank blue chart labeled '{...}' and a blank gray chart labeled...
3) Put the up-to-date data in a new blog entry with it's own analysis - and correct this blog entry now you have filtered data.
The PHP results are negatively biased. Production PHP websites and applications use opcode caching via 3rd party extensions such as APC and EAccelerator to improve the speed of code execution, sometimes quite dramatically.
hopeseekr > opcode caching via 3rd party extensions
When you have some examples of the performance improvement on the programs shown in the benchmarks game, and when you show how those 3rd party extensions are to be used with command-line PHP... Feature Request
When you have some examples of the performance improvement on the programs shown in the benchmarks game, and when you show how those 3rd party extensions are to be used with command-line PHP... Feature Request
Guillaume Marceau > Clean is a lazy language...
Clean is lazy and strict - there's a strictness analyzer, and types can be explicitly annotated strict
Clean is lazy and strict - there's a strictness analyzer, and types can be explicitly annotated strict
In some cases this is more about different compilers, not the languages. For example, Intel's C++ compiler very often outperforms GNU C++, but still GNU C++ is used to "represent" C++. It would have been interesting to see icc there.
Why do people consider tail-call optimization to be a functional language feature? Isn't it just an optimization that happens to be particularly effect in functional languages?
I've seen this usage elsewhere too, and it has always baffled me.
I've seen this usage elsewhere too, and it has always baffled me.
Python -- a language that supports list comprehensions, map/reduce, iterators, closures -- is listed as lacking functional features?
And (almost) same with Perl...
And (almost) same with Perl...
Scala is a hybrid Object-Oriented/Functional Programming language on the JVM. When I heard that Twitter was using Scala, I was curious and started collecting all the sites and articles to learn scala programming. If you are interested check the link below for the big list I have gathered (more than 200 sites) for learning scala programming.
http://markthispage.blogspot.com/2009/06/more-than-100-sites-to-study-scala.html
http://markthispage.blogspot.com/2009/06/more-than-100-sites-to-study-scala.html
The shoutout is great but lack more "high level" algorithm. There is very few bench that test threads, very few that test real object programing.
This introduce bias toward simple imperative langage like C.
This introduce bias toward simple imperative langage like C.
How can Python be marked as least compact in its performance class and Python 3 as the most compact in its performance class, when Python 3 is basically an extension of Python? Any program that works on Python can be written just as compactly, possibly more compactly in Python 3.
Thanks for this useful information. It is very informative and hence people who will come across this site will gain lot of information about it. I like this site, as it was being useful to me. I will visit this site in future too.
glucosamin
glucosamin
geez. Most languages do not have full set of benchmarks, you see. Consequently, looking at this chart, you're comparing apples versus oranges, i.e. one set of benchmark to another.
Also, you ought to notice that the only functional programming languages in first column are those with very few benchmarks.
To put it bluntly, naturally, the suckiest languages, which don't even have a lot of fanbois, will have only the easiest to write, fastest benchmarks present, which makes those languages look a lot better.
Also, you ought to notice that the only functional programming languages in first column are those with very few benchmarks.
To put it bluntly, naturally, the suckiest languages, which don't even have a lot of fanbois, will have only the easiest to write, fastest benchmarks present, which makes those languages look a lot better.
it's good to see this information in your post, i was looking the same but there was not any proper resource, thanx now i have the link which i was looking for my research.
UK Dissertation Writing
Post a Comment
UK Dissertation Writing
<< Home
![]()
Subscribe to Posts [Atom]